Context Graph vs RAG: Why Retrieval Can't Run Operations

Your team ships a RAG-powered assistant into production. It summarizes contracts in seconds. It drafts customer replies from your knowledge base. It finds the right policy paragraph in a five-hundred-page handbook. Leadership is impressed.
Then someone asks it to handle a claim that depends on three emails, two SAP entries, one handwritten note, and an exception the CFO approved last quarter. The assistant retrieves a dozen documents. It generates a confident summary. And it gets the decision wrong.
That gap is the point of this article. Retrieval-augmented generation is a brilliant way to find information. It is not a way to run operations. The distinction between a context graph and RAG is the distinction between a library and an operating system.
The bottom line: RAG is built for document lookup. A context graph is built for operational execution. Most enterprise AI pilots fail because teams use the first to solve problems that need the second.
The Core Difference: Retrieval vs Decision Logic
A context graph is a structured, continuously updated representation of how a business actually works. It captures which messages trigger which processes, which people make which decisions, which systems update which records, and why each decision was made the way it was.
RAG is a retrieval layer. It takes a query, turns it into a vector, pulls back documents that look similar in meaning, and hands them to a language model to compose a response.
The two solve different problems. RAG answers "what do we know?" A context graph answers "what do we do, and why?" For enterprise operations, only the second question leads to automation that holds up in production.
What RAG Actually Does (And Where It Stops)
How a Vector Retrieval Pipeline Works
RAG has three steps. Documents are chunked and embedded into a vector index. A user query is embedded and matched against that index for semantic similarity. The top-k chunks are passed to an LLM along with the query, and the model generates an answer grounded in those chunks.
This works well for one class of task: knowledge-intensive question answering against static or slowly changing content. Policy lookup. Contract summarization. Internal documentation search. MarketsandMarkets estimated the RAG market at 1.94 billion dollars in 2025 and projects 9.86 billion by 2030 at a 38.4 percent CAGR. That growth is real. The use case is real. What is also real is where the architecture stops.
The Operational Blind Spots of RAG
RAG's architecture assumes documents are the unit of truth. In operations, the unit of truth is the decision. And decisions leave almost no trace in document form.
When a customer service lead decides to escalate a specific complaint, the decision forms in a Teams thread. It is shaped by a mental model built from handling twenty similar cases. It is executed in Salesforce and Outlook. None of that becomes a clean document a retriever can find. RAG chunks what was written down. It cannot chunk what was thought through.
A 2026 analysis in Medium's Reliable Data Engineering publication reported that between 40 and 60 percent of enterprise RAG implementations never reach production. Chunking breaks context. Over-retrieval surfaces near-matches that are not actually relevant. And LLMs, even when handed the correct evidence, routinely fail multi-step reasoning across retrieved passages.
What a Context Graph Captures That RAG Can't
Decision Logic as First-Class Data
A context graph stores decisions, not just documents. When a purchase order arrives, the graph records the intent classification, the extraction of relevant business data, the applied decision rules, and the system actions taken. Next time a similar order arrives, the system does not retrieve a document "about" that order. It reconstructs the decision path.
That is the fundamental shift. RAG treats information as the payload. A context graph treats the decision as the payload, with information as its supporting context.
Causal Sequences and Temporal Reasoning
Enterprise operations are causal chains. An email triggers a case. A case blocks an SLA. An SLA violation escalates to a manager. A manager's approval updates an ERP field. A context graph captures that sequence with timestamps and attribution. RAG, by design, treats each document as an independent entry.
That difference matters most in regulated industries. An auditor does not ask "what documents did you find?" They ask "why did this decision get made on that day, by that person, based on what inputs?" A context graph has an answer. A RAG pipeline has a guess.
Cross-System Binding
Most enterprise decisions pull data from more than one system. A shared inbox, SAP, Salesforce, a document management system. RAG can retrieve chunks from each if they are all indexed. It cannot tie them into a single operational view.
A context graph binds messages, transactions, CRM objects, and workflow steps into one structure. That is what separates it from a knowledge graph, which stores facts about entities but not the decision logic that binds those facts together. It is also why Process Mining has to work across CRM and ERP simultaneously, and why treating email as its own silo never produces operational AI.
Context Graph vs RAG: Side-by-Side Comparison
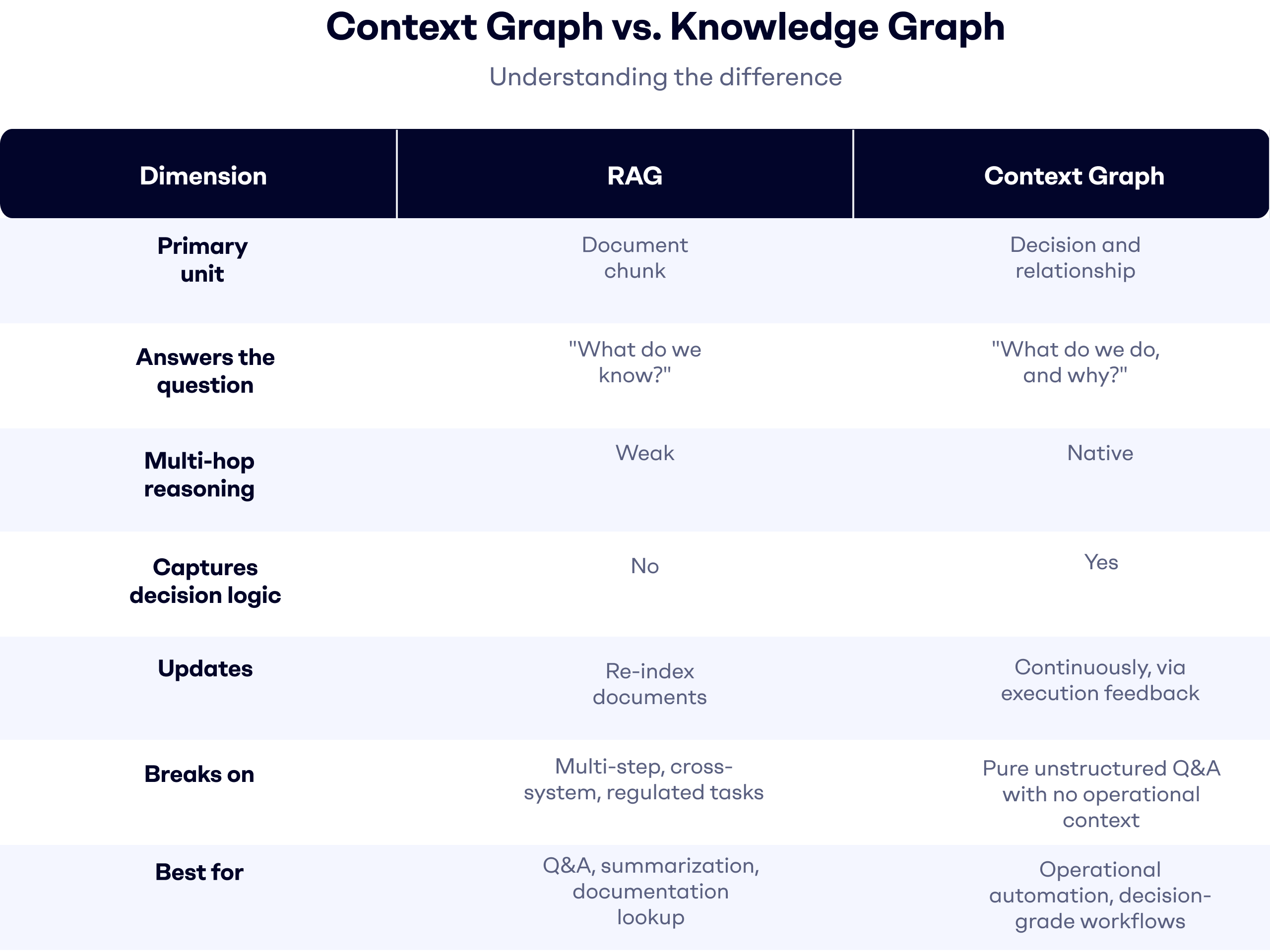
Why Retrieval Alone Breaks in Enterprise Operations
The "Why Did We Decide That?" Problem
RAG can surface a policy. It cannot explain why your team interpreted that policy one way for a premium customer and another way for a standard one. That judgment lives in the context graph or it lives nowhere. If it lives nowhere, no agent can replicate it consistently.
This is the deepest limitation of beyond retrieval augmented generation enterprise implementations. They retrieve information that lacks the operational memory of how work actually gets done. You can throw a larger model at the problem. It will not help. The signal the model needs is not in the documents.
The Multi-Step Workflow Problem
Enterprise workflows are rarely one prompt and one answer. An order intake flow runs through classification, extraction, validation, exception handling, and ERP write-back. A Q4 2025 benchmark reported by InfoQ on hierarchical RAG in financial services, across roughly fifteen hundred multi-hop queries, found that about thirty percent of queries failed silently. Authoritative-looking answers omitted more than twenty percent of the relevant data points. The retrieval layer worked. The reasoning across what it retrieved did not.
The Audit and Explainability Problem
Compliance teams do not block AI deployments because the model is imprecise. They block them because the model cannot explain itself. A context graph produces a decision trace: input, classification, rule, extraction, action, outcome. You could describes this as "auditability by design: every agent action is grounded in observable process data and traceable decision logic."
In regulated industries, that is not a nice-to-have. It is the difference between a pilot and a production deployment.
When RAG Is Enough and When You Need a Context Graph
RAG is the right starting point when the task is knowledge retrieval against a mostly static corpus, single-turn queries, no cross-system dependency, and no audit requirement tied to business rules. Documentation chatbots, internal search, contract Q&A. RAG is built for those.
A context graph is the right foundation when the task is operational execution, multi-step workflows, cross-system coordination, regulated outputs that need traceability, or any scenario where the same decision needs to be made consistently a thousand times a week. Order intake. Claim handling. Accounts payable. Shared inbox operations. These are context graph problems dressed up as retrieval problems, and treating them as the latter is why so many pilots stall.
Most enterprises do not need to choose between the two. They need to sequence. Start with RAG for genuine retrieval use cases. Build a context graph wherever the work looks less like a library lookup and more like running a process.
Building Operational AI on a Context Graph Foundation
The reason to treat the context graph as infrastructure rather than a feature is visible in the customers that made it work.
Becton Dickinson went live in three weeks, handling 1.4 million inquiries per year across more than fifteen languages, with 87 percent faster response times and no headcount added. Tenneco collapsed eight fragmented EMEA regions into one unified operation at 95 percent classification accuracy. Securex moved 3.2 million emails through automated routing at 90 percent accuracy within weeks, not quarters. Milcobel cut first-response time on 250,000 emails per year by 200 percent.
None of those numbers come from smarter retrieval. They come from a cross-system context graph, the foundation Tekst has built for enterprise operations, feeding a model that classifies intent, extracts the right business data, applies decision logic, and executes in the enterprise systems of record, not in a chatbot window.
RAG keeps its place. Document Q&A is not going anywhere. But the question driving the next phase of enterprise AI is not which model you use. It is what context you give it. If the answer is "whatever the retriever finds," you are building a better search tool. If the answer is "the live, auditable, decision-logic-carrying map of how this operation actually runs," you are building operational AI.
RAG retrieves information. A context graph runs operations. That is the distinction that decides which projects scale past the demo.



Discover the impact of AI on your enterprise. We're here to help you get started.